
Indice:
- Un grande malinteso
- Come funziona ChatGPT
- Cosa dice il provvedimento del garante
- Il garante può far chiudere un’azienda?
- Privacy, la punta dell’iceberg
- Cosa succede adesso?
Un grande malinteso
In questo momento di clamore sulla cosiddetta intelligenza artificiale (che non è né intelligente, né artificiale) è necessario alzare ogni giorno barriere per difendersi da proclami tanto fumosi quanto assertivi sulle sue potenzialità dirompenti – sempre future, sempre generiche – e stare ben ancorati nella realtà dei rischi che essa pone: ben documentati, specifici e presenti.
Quando si parla di “IA generativa” (come ChatGPT, per intenderci rapidamente) sembriamo poi soffrire di una amnesia collettiva: questa tecnologia, tramite sistemi statistici chiamati grandi modelli di linguaggio, è in grado di produrre scritti e immagini così plausibili da far dimenticare anche a chi li conosce i meccanismi sottostanti.
Dal 30 marzo 2023 c’è ancora più confusione ed emerge il divario di conoscenza tra chi utilizza sistemi come ChatGPT, chi li regola e chi li produce. La confusione aggiuntiva arriva a causa di un provvedimento del Garante per la privacy, che ha ingiunto a OpenAI, l’azienda produttrice del software, di sospendere il trattamento dei dati personali delle persone stabilite sul territorio italiano e le ha dato 20 giorni per giustificare le violazioni e rimettersi in regola.
OpenAI ha reagito bloccando il servizio sul territorio italiano, come comunicato da Sam Altman, il suo amministratore delegato, in un tweet di venerdì:

Il Garante non è stato il primo né l’unico ad aver notato che ChatGPT non è (e forse non potrà mai essere) conforme al regolamento europeo per la privacy, ma è stato il primo ad agire concretamente contro OpenAI.
Dato che la reazione dell’azienda è stata rapida e già a poche ore dal provvedimento non era più possibile accedere al servizio dall’Italia, molti ne hanno concluso che il Garante avesse la facoltà di bloccare ChatGPT. Questo ha provocato reazioni indignate ma fuori squadra: si sono levati lamenti sulla scarsa lungimiranza dell’Italia, paragoni del nostro Paese con Cina, Iran e Corea del Nord quanto a censura, richieste di ripristinare il servizio immediatamente, raccolte di firme e petizioni con toni di urgenza che forse meriterebbero una causa diversa.
Non è così: il Garante non ha la facoltà di chiudere un’azienda in 24 ore e nemmeno ne ha richiesto la chiusura, e lo vedremo tra poco leggendo insieme il testo del provvedimento. Ma prima di andare alla fonte è utile dire due parole su come funzionano ChatGPT e le IA conversazionali (cioè i chatbot) di ultima generazione che si basano sulla stessa tecnologia.
Come funziona ChatGPT
ChatGPT è un modello stocastico che ha “imparato a scrivere” grazie a due fasi di addestramento: la prima, il pre-addestramento, è stata fatta su un enorme blocco di testo, ottenuto mettendo insieme milioni di testi diversi – articoli, libri, Wikipedia, e altri testi online. In questa fase il modello si è addestrato “imparando” in modo autonomo, senza supervisione umana, a prevedere le parole mancanti di diverse combinazioni di testo incomplete, che gli sono state nascoste e poi rivelate. Una volta completato il pre-addestramento, c’è una seconda fase di rinforzo umano in cui gli utenti del modello possono valutare la bontà delle risposte attribuendo loro un pollice su o giù.
In questo modo il sistema ha acquisito l’abilità di fare congetture plausibili (l’etimologia della parola stocastico rimanda appunto a “congetturale”), indovinando la concatenazione di parole più probabile per soddisfare una determinata richiesta, basandosi sul testo che gli è stato fornito nella fase di addestramento e i riscontri ricevuti successivamente.
Anche se OpenAI non dichiara con precisione i testi utilizzati, nel calderone sono finiti 300 miliardi di parole, che corrispondono a 570GB di dati ottenuti da testi di qualunque tipo disponibili online, libri, articoli e Wikipedia (fonte). I testi sono stati utilizzati per l’addestramento senza chiedere il consenso a chi li ha prodotti, e nel corpus di addestramento ci sono naturalmente anche dati personali e sensibili.
Nel comporre una risposta, ChatGPT mette assieme parole provenienti da testi diversi, che sono state raggruppate dal modello. Questo è il motivo per cui i suoi enunciati possono essere sbagliati, anche se risultano sempre corretti dal punto di vista sintattico e grammaticale: e quando a essere falsi sono enunciati che riguardano persone esistenti ci troviamo di fronte a una violazione del GDPR. Di quest’ultimo argomento parleremo più estesamente tra poco.
Cosa dice il provvedimento del garante
Il provvedimento del Garante ha sollevato i seguenti punti, in violazione degli articoli 5, 6, 8, 13 e 25 del GDPR (per chi ne avesse voglia, qui si può scaricare il testo in italiano del Regolamento):
- ChatGPT non informa gli utenti i cui dati personali sono stati utilizzati per il suo addestramento né riceve il consenso al trattamento;
- Non sembra esserci una base giuridica sufficiente per l’utilizzo di dati personali per l’addestramento del software;
- Quando ChatGPT riporta informazioni su una persona, queste non sono sempre esatte né si possono rettificare e
- Manca un’adeguata verifica per impedire l’accesso al servizio ai minori di 13 anni.
Il provvedimento passa poi a disporre “la misura della limitazione provvisoria del trattamento dei dati personali degli interessati stabiliti nel territorio italiano”, e dà a OpenAI 20 giorni per comunicare come ha iniziato a risolvere i problemi indicati e giustificare le violazioni, pena una sanzione amministrativa, cioè una multa.
A chiudere il provvedimento un paragrafo che specifica che OpenAI ha facoltà di opporsi entro 60 giorni dalla ricezione dell’avviso.
Il garante può far chiudere un’azienda?
No. La decisione di bloccare il servizio sul territorio italiano è stata presa da OpenAI, che ha scelto questa tra altre possibilità di azione.
Non sappiamo perché l’azienda abbia agito così impulsivamente, ma probabilmente un’eccessiva fede nel proprio prodotto, una scarsa rilevanza percepita del mercato italiano e una certa noncuranza verso le leggi (l’innovazione non si può fermare) possono contribuire a spiegare la sua decisione. Assieme al fatto che, per come funzionano queste tecnologie, è molto difficile soddisfare le richieste del Regolamento.
Il Garante è un’autorità di controllo e non ha la facoltà di bloccare i servizi di un’azienda. Si possono leggere i suoi compiti qui, ma basterebbe anche fermarsi a riflettere sul fatto che le grandi aziende tecnologiche sono quasi tutte in violazione, chi in un modo chi in un altro, del GDPR, hanno procedimenti legali in corso e nonostante ciò continuano a operare sul territorio europeo.
Privacy: la punta dell’iceberg
Quelli di privacy e del trattamento dei dati personali sono solo alcuni dei problemi che l’utilizzo diffuso dei grandi modelli di linguaggio possono portare. Ne discutiamo alcuni altri qui di seguito.
1.Errori e falsità
Una delle preoccupazioni forse più note sui sistemi come ChatGPT è che spesso dicono cose prive di fondamento. Come anticipato nei paragrafi precedenti, ciò accade non perché il modello sia intenzionalmente ingannevole, ma perché le risposte sono la più probabile concatenazione di parole basata sul corpus di dati usato per l’addestramento, che non è necessariamente quella corretta.
ChatGPT è stato scherzosamente definito un “cazzaro” (in questo articolo di Dan Macquillan, autore di Resisting AI) perché mente senza sapere o preoccuparsi di mentire; e anche se la maggior parte delle volte risulta innocuo, è facile immaginare come fidarsi ciecamente delle sue risposte possa causare problemi anche gravi, oltre a violare il GDPR quando le risposte sbagliate riguardano persone fisiche.
In quest’ultimo caso, quando il modello “impasta” le nostre informazioni con quelle di altre fonti, può creare dei Frankenstein fallaci sul nostro conto (ha persino insistito sul fatto che un suo utente fosse morto, cosa che ha portato lo stesso utente ad augurarsi la morte del chatbot, invece).
Dal momento che una volta che il modello è stato addestrato, indietro non si torna, il diritto all’oblio sembra essere un’altra delle trappole di ChatGPT e sistemi simili, e non è chiaro come possa essere realizzato.
Oltre ad aver sconcertato diverse persone, sembra che la tendenza all’imprecisione dei modelli di linguaggio abbia già creato danni finanziari ingenti. Nel febbraio 2023, Google ha utilizzato un video promozionale per mostrare le capacità di Bard, il suo chatbot, che conteneva informazioni sbagliate. È stato detto che il successivo, significativo calo delle azioni di Alphabet, che ha intaccato il valore di mercato dell’azienda per 100 miliardi di dollari, sia stato causato proprio dall’annuncio.
2.Pregiudizi e discriminazioni
Ancora una volta, questi problemi hanno a che fare con la natura statistica del modello, che cerca ed estrapola regolarità nelle banche dati utilizzate per addestrarlo e fa derivare le sue ipotesi dalla distribuzione di questi dati. Nel caso dei modelli linguistici, i dati sono testuali, e i testi sono stati prodotti in contesti socio-culturali specifici, da persone con caratteristiche specifiche, e non sono necessariamente rappresentativi o equi.
Si può fare un esempio di queste distorsioni anche con metodi predittivi più semplici che si basano però su tecnologie simili, ad esempio il suggerimento della parola successiva fatto dalla tastiera predittiva dell’iPhone, come nel caso reale riportato sotto:
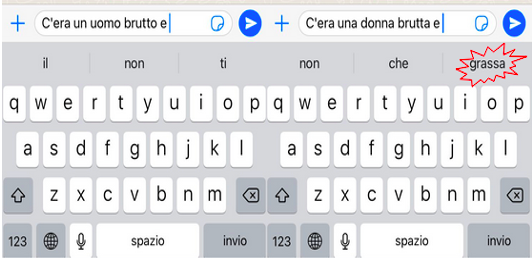
In questo esempio, il fatto che la parola “grassa” sia suggerita dopo la parola “brutta” ma non dopo la parola “brutto” potrebbe rivelare involontariamente un pregiudizio verso la grassezza femminile, che viene automaticamente associata alla bruttezza.
Anche se i modelli migliorano costantemente sotto questo aspetto perché gli enunciati offensivi o discriminatori vengono prontamente segnalati e corretti, è comunque importante sapere che, specialmente su argomenti non comuni, possono agire in modo imprevedibile e produrre risposte distorte. Inoltre, le operazioni necessarie per rendere l’IA conversazionale più robusta e affidabile non sono sempre etiche, come evidenziato, tra gli altri, da un articolo che ha indagato sul lavoro alla base della creazione di uno strumento per eliminare i contenuti tossici dal set di dati di addestramento. Il che ci porta al prossimo argomento, i problemi relativi allo sfruttamento del lavoro.
3.Sfruttamento del lavoro
L’articolo del Time OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic indaga sulle condizioni di lavoro dei lavoratori kenioti impiegati per segnalare testi offensivi, volgari etc. al fine di creare uno strumento automatizzato per rendere ChatGPT più sicuro.
La pratica di impiegare lavoratrici e lavoratori nel Sud del mondo per rilevare e filtrare i contenuti online non adatti non è una prerogativa di OpenAI: è stata utilizzata da piattaforme come YouTube e altri social media, in particolare Facebook, per la moderazione dei contenuti, e gli scandali sulle discutibili condizioni di lavoro e le ripercussioni psicologiche di questo settore lavorativo sono già emerse anni fa (vedi ad esempio il documentario PBS del 2018 “The Cleaners”). Secondo l’articolo del Time, «l’intelligenza artificiale fa spesso affidamento sul lavoro umano sommerso nel Sud del mondo che spesso danneggia e sfrutta i lavoratori. Questi lavoratori invisibili rimangono ai margini anche se il loro lavoro contribuisce a settori da miliardi di dollari». Mentre è stato giustamente sottolineato che lo stipendio dei lavoratori e le lavoratrici che moderano ChatGPT era più alto della media in Kenya, rimane comunque degno di nota il fatto che è difficile in Occidente reperire persone per portare a termine il lavoro di routine e spesso traumatico di “disinfettare” il materiale di formazione, e che avvantaggiarsi di normative sul lavoro più rilassate nei paesi più poveri, anche quando legale, non è una pratica etica.
4.Emissioni di carbonio
Anche se le aziende rimangono abbottonate sull’argomento, ci sono diverse stime che dimostrano che l’addestramento e il funzionamento dei grandi modelli di linguaggio richiedono una quantità significativa di energia elettrica, moltissima acqua per raffreddare i centri dati che ospitano le macchine e risorse minerali per costruire i chip e le macchine, con ripercussioni sull’ambiente e la biodiversità difficili da calcolare ma senz’altro rilevanti.
5.Proprietà intellettuale, segreti aziendali e diritto d’autore
Non sono solo i privati ad essere interessati a come viene utilizzato il loro materiale senza un esplicito consenso. Dicevamo che il corpus di dati usato per addestrare ChatGPT è considerato un’informazione strategica di proprietà di OpenAI, e pertanto non viene divulgato. Ma è facile immaginare che, se l’IA può scrivere un racconto nello stile di Stephen King, può farlo in virtù del fatto che almeno alcuni dei suoi libri sono stati usati per addestrarla. Ancora più sfacciatamente, il software è in grado di citare testualmente interi paragrafi di libri.
La violazione del diritto d’autore non si ferma a libri e articoli: OpenAI sta già affrontando almeno una causa per pirateria di software, perché l’abilità di ChatGPT di produrre righe di codice deriva dall’ingestione del lavoro collettivo di sviluppatori che hanno reso disponibili i loro contenuti online o li hanno distribuiti con licenza libera. Simili preoccupazioni e indignazione per la violazione del diritto d’autore sono state espresse per quanto riguarda la generazione di immagini e musica, abilità resa possibile grazie al lavoro di artisti umani. TechCrunch ha esaminato il panorama delle cause intentate fino alla fine di gennaio 2023 in questo articolo.
Oltre alla proprietà intellettuale e al diritto d’autore, c’è l’ulteriore problema preoccupante che comandi composti con intenzioni malevole possono portare il chatbot a divulgare segreti commerciali e informazioni riservate che sono state risucchiate nel suo database di addestramento.
Tutti questi aspetti stanno mettendo in allerta gli avvocati e ChatGPT è già stato scoraggiato o addirittura bandito da alcune aziende, come Amazon e JPMorgan Chase.
6.Problemi aggiuntivi
Oltre a quelli sopra elencati, ci sono problemi più generali e sottili riguardo alle IA che sono in grado di imitare il linguaggio umano. Nonostante abbiano un impatto meno immediato, vale la pena sottolinearli perché possono avere conseguenze difficili da prevedere su persone e società e creare effetti potenzialmente indesiderabili a lungo termine.
Antropomorfizzazione e dipendenza eccessiva
È noto che, a partire dal primo strumento utilizzato dagli umani alla prima IA conversazionale, ELIZA, le persone tendono a proiettare la capacità di pensare e persino di provare sentimenti sui propri artefatti. Come quando immaginiamo sembianze umane in una nuvola, desideriamo che un nostro artefatto sia come noi anche se ne conosciamo il funzionamento, soprattutto quando ha delle caratteristiche che ci somigliano in modo convincente (è meno facile umanizzare un frigorifero o un aeroplano che una bambola o, appunto, un chatbot). Perché questo dovrebbe essere motivo di preoccupazione? Il centro di ricerca sull’IA Deepmind, in un documento che copre i rischi derivanti da modelli di linguaggio di grandi dimensioni, porta la nostra attenzione sui “danni dell’interazione uomo-computer”. Questi si manifestano quando gli utenti giudicano male o si fidano ingenuamente dei sistemi di intelligenza artificiale perché gli attribuiscono caratteristiche umane, esponendosi a essere sfruttati o ingannati, sia intenzionalmente (se il chatbot è operato da malintenzionati) che involontariamente.
Per un esempio (piuttosto avvincente) di potenziale danno da interazione uomo-computer, questo pezzo del NY Times in cui lo scrittore intervista il chatbot integrato nel motore di ricerca Bing è un buon punto di partenza.
Impatto sull’autonomia e l’agentività umane
L’autonomia può essere definita come la capacità di scegliere e di agire in base alle nostre scelte, ed è stata collegata alla soddisfazione che proviamo per la nostra vita. Come ha sostenuto Joseph Weizenbaum nel suo libro “Computer Power and Human Reason”, l’intelligenza artificiale potrebbe essere un fattore che contribuisce al declassamento della scelta, un’attività complessa e profondamente umana che tiene conto della nostra storia, i valori, le credenze. Se è computazionale, la scelta perde corpo e diventa decisione, un processo più meccanico che seleziona le opzioni in base alla valutazione di fattori esterni e all’ottimizzazione.
Quando iniziamo a fare troppo affidamento su prodotti come ChatGPT per raccogliere informazioni e valutare le diverse opzioni, potremmo perdere la fiducia nella nostra capacità di scegliere. Se è vero poi che le nostre scelte contribuiscono alla formazione della nostra identità, e avere un forte senso di identità contribuisce alla nostra soddisfazione e felicità complessiva, perdere l’abitudine di fare scelte potrebbe renderci meno felici, un rischio difficile da quantificare, ma esistenziale.
Certo, si potrebbe dire che un chatbot “etico” potrebbe aiutare a prendere le distanze da scelte dannose o violente prese in modo autonomo, ma noi crediamo che anche questa funzione di mitigazione dovrebbe rimanere prerogativa della società e non della tecnologia, o quantomeno invocata solo quando si fossero esplorate tutte le altre possibilità.
Cosa succede adesso?
È davvero troppo presto per dirlo, e molto dipenderà da come reagiranno le altre autorità garanti per la privacy in Europa. Senz’altro nell’ultima settimana, tra i botta e risposta di lettere aperte (Future of Life e DAIR institute) e il vespaio sollevato dal provvedimento del Garante, il dibattito sui modelli di linguaggio ha subito un’accelerazione notevole.
L’entusiasmo per le tecnologie generative, la loro diffusione, la semplicità d’uso, la narrazione di inevitabilità che le accompagna, le promesse utopiche, le reazioni dei governi che hanno iniziato una sorta di corsa agli armamenti per quanto riguarda la cosiddetta “intelligenza artificiale” fanno presagire però che dovremo occuparci di questi temi ancora a lungo.
È un peccato, perché sembra che molta intelligenza umana si stia spendendo su un argomento tutto sommato secondario, invece che concentrarsi su temi più concreti e immediati, uno tra tutti la crisi climatica: una distrazione rischiosa.